During our initial consultations, it became clear that the company’s existing setup was holding back scalability. While their platform had strong potential, several structural gaps made it difficult to integrate AI modules, automate processes, and maintain quality at speed.
The infrastructure lacked clarity and scalability, making it challenging to extend or integrate with new AI-driven features.
Reports and policy documents were generated manually, consuming significant time and effort while limiting the ability to customize outputs.
There was no intelligent workflow to extract domain-specific data and generate structured outputs automatically. This gap created productivity bottlenecks across teams.
Without a unified testing and feedback environment, iterative improvements were slow, and final output quality often suffered.
To address these blockers, our team followed a structured 5-phase approach, ensuring every step aligned with the company’s goals while setting up scalable foundations for future AI-related enhancements.
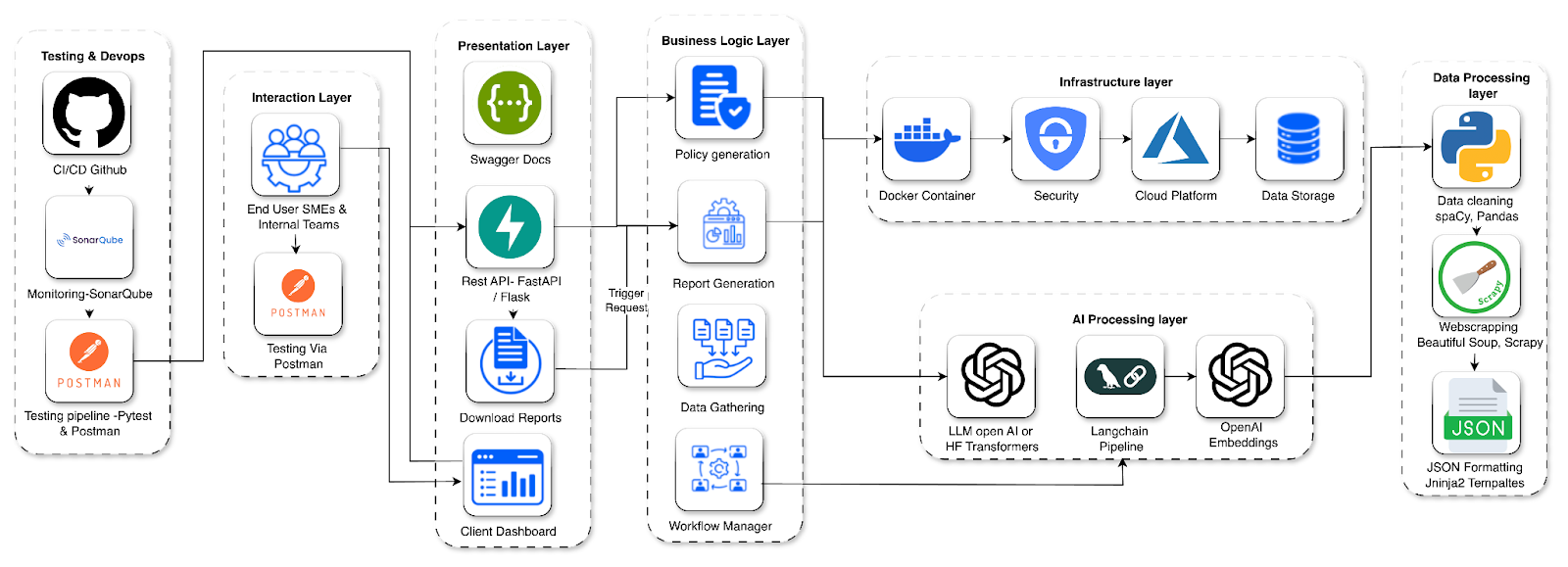
We began with detailed code walkthroughs and knowledge transfer sessions to map existing gaps. API logic was refactored using FastAPI and Flask for seamless LLM integration. Endpoints were fully documented with Swagger and tested rigorously using Postman for reliability.
A Hugging Face Transformers model was fine-tuned for domain-specific use cases, with LangChain enabling prompt engineering and structured chaining of outputs. RESTful APIs were built to programmatically deliver recommendation reports in standardized JSON formats.
For policy automation, we used Pandas and spaCy for data cleaning and preprocessing, while OpenAI GPT-3.5 and Azure OpenAI Service generated template-based drafts. Jinja2 was applied for dynamic JSON formatting and automated policy templating.
To expand content coverage, we integrated BeautifulSoup and Scrapy for third-party data extraction. Retrieved content was semantically processed through the OpenAI Embeddings API, then organized into standardized JSON outputs using predefined schemas.
A centralized testing framework was set up using PyTest and Postman Collections. CI pipelines via GitHub Actions ensured automated testing and version control, while Jira and Notion were used to log issues and enhancements for sprint-based delivery.
APIs deployed on AWS Lambda or Azure Functions.
All components are Dockerized for easy scaling and portability.
Models fine-tuned and deployed with Hugging Face and Azure OpenAI.
LangChain was used for prompt flows and tool integration.
Data preprocessing handled with spaCy and Pandas.
Reports and policies generated by LLMs, formatted using Jinja2.
FastAPI-based REST APIs with OAuth2 security.
AES-256 and TLS encryption for data security.
RBAC for controlled API and dashboard access.
Ongoing audits and scans with SonarQube.
End-to-end automation cut cycle time by about 60% down from 5 days to 2, so the same team now ships 50 reports/policies a month instead of 20.
Fine-tuned LLMs increased acceptance of suggested actions by 30% (roughly 46 to 60 accepted per 100). Average edit time per recommendation dropped from 18 minutes to 9 minutes.
Automation removed 70% of manual touchpoints, freeing over 400 staff hours per quarter, about 6-8 hours per analyst each week for higher-value work.
The feedback loop shrank from 72 hours to under 6 hours. Model and prompt updates moved from 1 release per week to 3, enabling a quicker improvement cycle.
With automation, explainability, and faster iteration cycles in place, the client’s teams can focus less on chasing reports and more on innovation. In short, what used to feel like a bottleneck has become a growth engine for smarter decisions.
Technology & Software
US
End to End Project Lifecycle Management
Briefly describe the challenges you’re facing, and we’ll offer relevant insights, resources, or a quote.

Business Development Head
Discussing Tailored Business Solutions
DataToBiz is a Data Science, AI, and BI Consulting Firm that helps Startups, SMBs and Enterprises achieve their future vision of sustainable growth.
DataToBiz is a Data Science, AI, and BI Consulting Firm that helps Startups, SMBs and Enterprises achieve their future vision of sustainable growth.

















